Llevo un par de semanas con varias sesiones de Claude Code abiertas a la vez sobre el mismo proyecto. Una le da caña al pipeline de tags, otra está retocando el frontend, otra escribe documentación. 🙂
Suena bien sobre el papel, pero la primera vez que lo intenté en serio me encontré con dos agentes editando el mismo HTML al mismo segundo y machacándose el output. Tuve que recuperar trozos a mano del historial. No fue divertido.
De ahí salió el semáforo: un fichero de texto plano en la raíz del repo donde…
- Cada agente apunta qué archivo va a tocar antes de tocarlo.
- Si ya está cogido por otro, espera.
- Cuando termina, borra su línea.
No hay servidor, no hay proceso vigilante, no hay nada montado encima del sistema operativo. Solo un .txt.
No me lo he inventado yo, leí acerca del sistema en Twitter, ahora no recuerdo a quién… y seguramente alguien que sepa un poco podría decir que es una chapuza y que es mejor organizar esto en ramas o worktrees… No sé.. A mí me funciona y es mi chapuza. 🙂
Cómo se ve el fichero en marcha
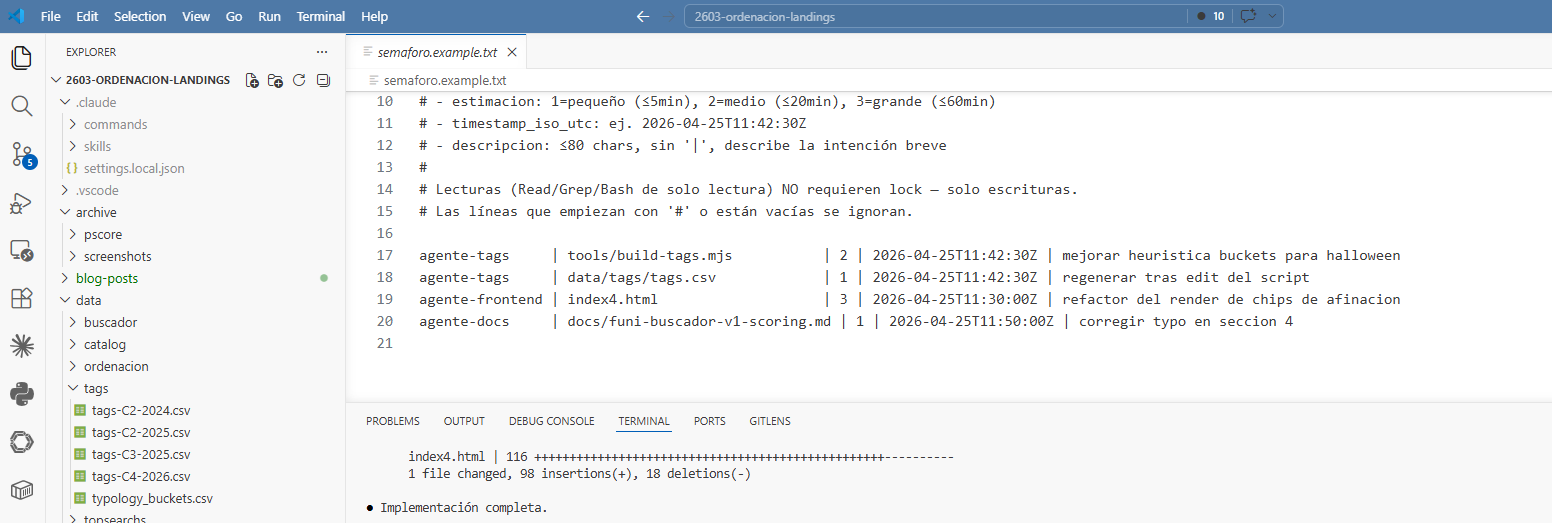
El formato no tiene misterio. Cinco campos separados por pipes: nombre del agente, ruta del archivo, una estimación de cuánto va a tardar (1, 2 o 3), el momento en que cogió el lock y una descripción corta de lo que está haciendo.
# semáforo activo — actualizado por los agentes en tiempo real
agente-tags | tools/build-tags.mjs | 2 | 2026-04-25T11:42:30Z | mejorar heurística buckets
agente-tags | data/tags/tags.csv | 1 | 2026-04-25T11:42:30Z | regenerar tras edit del script
agente-frontend | index4.html | 3 | 2026-04-25T11:30:00Z | refactor del render de chipsLa estimación es lo que más me ha gustado del diseño. No predice nada con precisión, pero le dice al resto cuánto esperar antes de volver a intentarlo. Un lock de nivel 1 (cambio pequeño) implica reintentar a los 15 segundos. Uno de nivel 2 (algo medio), a los 45. Uno de nivel 3 (refactor gordo), a los dos minutos. Tras siete intentos fallidos sobre el mismo archivo, el agente aborta y avisa. Sin drama, sin pelearse.
El detalle que casi rompe todo
La primera versión del protocolo tenía una grieta que tardé en ver. Los agentes, si creían estar solos, se saltaban la declaración del lock porque, ¿para qué molestarse?
El razonamiento parecía sensato: no hay nadie más, no hay con quién chocar, ahorrémonos las dos operaciones extra.
Pues no. Esa lógica rompe el sistema entero. Un agente nunca puede saber con seguridad que es el único activo. Tú, como humano, puedes haber abierto otra terminal con otra sesión cinco minutos antes y el agente actual no se entera. Si el «primero» no declaró su línea porque pensaba estar solo, el «segundo» llega, lee el semáforo, ve un fichero vacío y asume que el path está libre. Catástrofe silenciosa.
Por eso la especificación ahora deja una regla muy explícita: el protocolo aplica siempre, sin excepción, también cuando el agente cree estar solo. La ausencia de líneas en el semáforo solo significa «libre» si todos los agentes han cumplido su parte. En cuanto uno se la salta, el contrato se rompe para todos.
Un protocolo cooperativo solo funciona si todos cooperan siempre. La excepción «porque hoy no hay nadie más» es exactamente lo que lo invalida.
Casos raros que tocó pensar
En cuanto empiezas a usarlo en serio, aparecen los casos extremos. El más obvio es el lock zombie: un agente crashea, se desconecta o el usuario lo mata, y deja su línea ahí indefinidamente. La solución que adopté es un TTL implícito atado a la estimación. Si una línea de nivel 1 lleva más de X minutos viva, se considera muerta. Pero el agente que la detecta no la borra: avisa al usuario y procede declarando su propio lock encima.
El otro caso es la race condition al escribir. Dos agentes leen el semáforo a la vez, ambos ven el path libre, ambos escriben su línea casi simultáneamente. La mitigación es leer el fichero otra vez justo después de escribir tu línea. Si ves que hay otra línea para tu mismo path con timestamp anterior, perdiste la carrera, borras tu línea y te toca esperar. Si tu timestamp es el más antiguo, ganaste. Y si empata al segundo, gana el agente cuyo nombre va antes alfabéticamente. Determinismo barato y suficiente.
¿Hasta dónde llega esto?
La limitación grande es que necesita un sistema de ficheros compartido. Si cada agente corre en su propia máquina con su propio clon del repo, el semáforo no puede funcionar: cada uno está mirando un fichero distinto. Para esos escenarios toca pensar en algo diferente. Pero para mi setup, que es varias sesiones locales sobre el mismo working directory, esto cubre el 100% del caso.
Lo que más me sorprende es lo poco que pesa. Lo único que añades a cada edición es leer un .txt, escribir una línea y borrarla al terminar. A cambio, puedes lanzar tres o cuatro agentes en paralelo y olvidarte de que existen los conflictos. La especificación entera, con casos extremos y todo, vive en docs/sistema-semaforo.md del repo. Si tienes un setup parecido, copiarla y adaptarla no cuesta nada y te ahorra un susto de los buenos.
Te la dejo aquí.
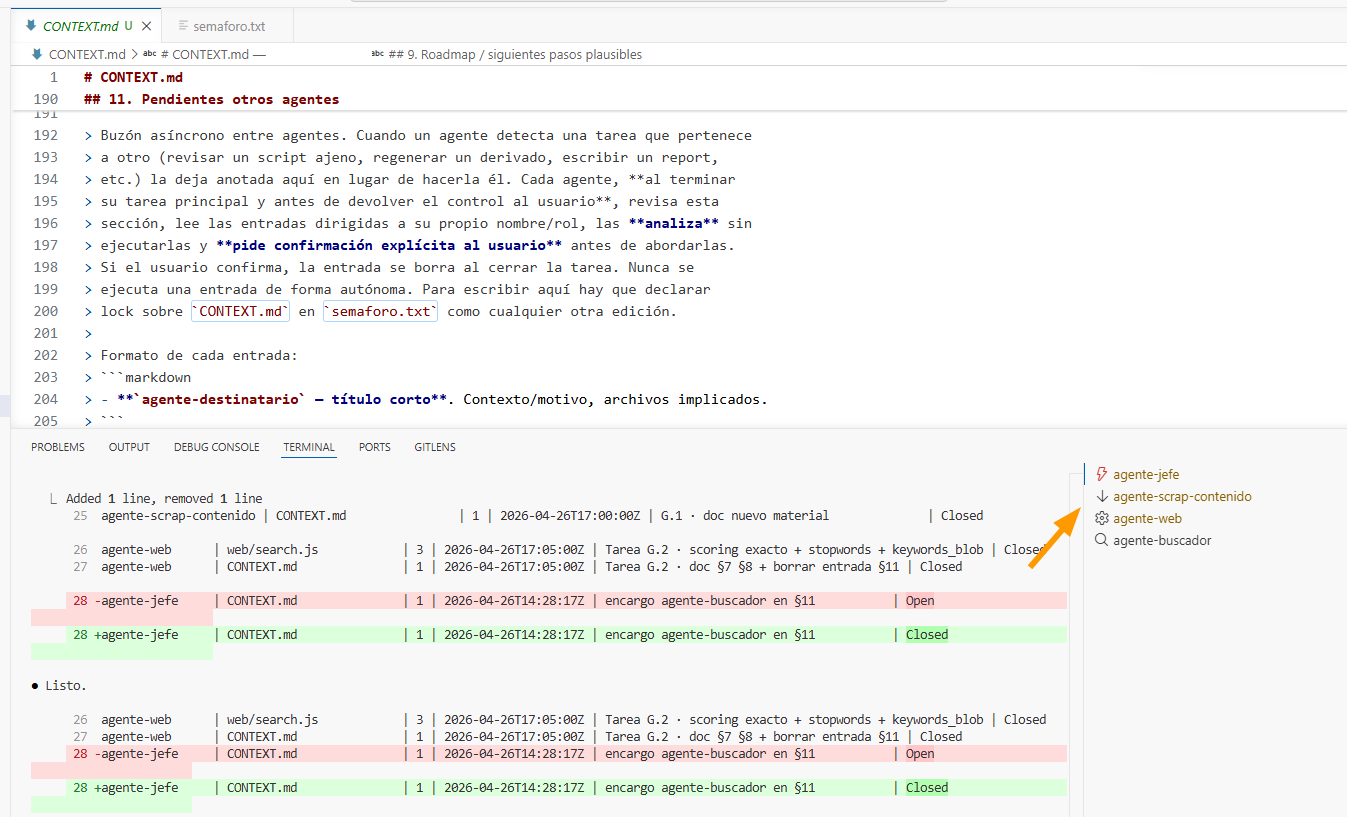
UPDATE: Ya he metido todo esto en una skill global. Y he añadido que las tareas no se borren, sino que tengan estado Open/Closed para guardar histórico. Y he creado la figura del agente-jefe u orquestador para organizar el trabajo del resto… De esto último, evidentemente, también había leído/oído, pero por mi momento de adopción actual y tamaño de los proyectos, no había llegado.